The Hidden Dimensions of the Musical Field and the Potential of the New Social Data
by David Beer and Mark Taylor
University of York; University of Manchester
Sociological Research Online, 18 (2) 14
<http://www.socresonline.org.uk/18/2/14.html>
10.5153/sro.2943
Received: 28 Jun 2012 Accepted: 15 Feb 2013 Published: 31 May 2013
Abstract
This article seeks to highlight what might be thought of as the hidden dimensions of the musical field and explores the potential of digital by-product data for illuminating the aspects of musical taste and preference that are difficult to see with traditional social science methods. It suggests that the limitations of existing field analysis create what might be thought of as darkened areas of music consumption that may remain outside of the gaze of the interested social scientist. The paper briefly discusses some of the analytical problems associated with this lack of visibility. In response this article focuses upon the specific example of Last.fm and looks to make use of the by-product data that this particular website accumulates about individuals' everyday music listening practices. From this specific example the article provides some substantive observations about the contemporary musical field and uses these to offer insights into the potentials and limitations of using by-product data in the analysis of (the musical) field. This article specifically questions the boundaries drawn around genre in the study of field, and looks at how these might be reported upon in alternative ways using new forms of data.
Keywords: Music, Field Analysis, Digital Data, Digital Methods, Genre, Musical Field, Cultural Tastes
Introduction
1.1 You might be forgiven for thinking that the UK was unusually highbrow in its tastes during late 2010. At least that is what you might have discovered if you were to have conducted some research on musical taste during that period. The level of enthusiasm for Wagner would have no doubt come as something of a surprise. This apparent highbrow interest would not though have been the product of a resurgent interest in one of Adorno's least favourite composers; it would instead have been the result of a large-scale engagement with the television singing competition The X Factor. Millions of viewers of this show tuned in to watch comedic performances by a Brazilian-born contestant named Wagner. Presenters on the national radio station BBC Radio 5 Live spotted an opportunity for a lay experiment in the cultural capital of people on the street. They asked simply what was thought of Wagner. The measure of cultural capital arose from which Wagner the interviewee interpreted this question to be referring to the comedic singer or the serious composer. This might appear to be a somewhat banal example of cultural capital in practice, but what it points towards are what we refer to in this article as the hidden dimensions of the musical field. These are the dimensions of field that sociological methods make it hard for us to see or, to put it another way, this is to accept that our existing methods 'enact' (Law 2004, 2009) or constitute field in a particular way. We will expand upon this in a moment, but in this example we can see that misunderstandings may easily shape the way we might report on something like cultural tastes and preferences. In this instance we might have misinterpreted an interest in opera were we not familiar with the references to popular culture.1.2 What we intend to do in this article is to look more broadly at elaborating upon such hidden dimensions of field, and particularly of the musical field. Once these hidden dimensions are established we will then explore the potential of digital forms of by-product data for revealing or illuminating some aspects of these dimensions. The central aim of this article then is to begin to open up some of the hidden dimensions of (the musical) field, the things that are difficult to see with traditional social science methods, and to reflect upon the potential of new forms of by-product data for revealing or illuminating these hidden dimensions. Existing accounts of the musical field understandably tend to rely upon survey- and sometimes interview-based data, with occasional inclusions of participation rates and the like. This article focuses upon the specific example of Last.fm and looks to make use of the by-product data that this particular website accumulates about individuals' everyday music listening practices. From this specific example the article provides some substantive observations about the contemporary musical field and uses these to offer insights into the potentials and limitations of using by-product data in the analysis of (the musical) field. In particular this article questions the boundaries drawn around genre in the study of field, and looks at how these might be reported upon in alternative ways using new forms of data. One clear advantage of by-product data is that they reveal what individuals and 'taste communities' are actually listening to rather than what it is that they report that they are listening to. Further to this, these data can also be used to provide insights into the genres that these listeners themselves actually associate with particular musical works.
The musical field and its hidden dimensions
2.1 There has been much written over recent years on the sociology of Pierre Bourdieu (for a discussion of Bourdieu's 'sociological stardom' see Santoro 2011). Many social scientists have found a good deal of mileage in his central concepts and analytical frameworks. We do not wish to provide another layer of detail to this already vast interpretative work, the reader can turn elsewhere for such a resource (for a really helpful summary of 'field' as compared to 'worlds' and 'networks' see Bottero & Crossley 2011). Instead this article responds to a general conception of field and particularly the musical field, to see if we may explore further opportunities for revealing the 'objective relations' that constitute it (Bottero & Crossley 2011: 101). So, instead of immersing the reader further in these debates we would like instead to borrow a helpful definition of field that will act to orientate the discussions that follow. In this instance we call upon Nick Prior:'Conceptually, the field is an immediate invitation to think relationally about the actions of social agents who, propelled by their habituses, compete for particular values specific to that field In Bourdieu's hands, then, the field becomes a network of objective relations between agents, but also larger groupings and institutions distributed within a space of possible positions. Its function is not merely to describe a logic of struggle between agents, but also a grander attempt to examine how modern societies are themselves defined by an architecture of overlapping spheres' (Prior 2008: 304305)Or as Bottero and Crossley (2011: 100) put it, 'any cultural arena is a field of forces, where underlying objective relations structure manifest social relationships'. Our article is about the potential of new types of digital data; rather than tie this to a very specific conception of field we would instead hope to leave this aspect of the article relatively open so that readers may see the value or potential of this data for whatever specific version or interpretation of field that they prefer.
2.2 Let us begin with what it is about the musical field that might be missed, obscured or even concealed by established sociological methods. We can reflect first upon three more blatant methodological points; these are relevant because they are matters that we might yet be able to partially overcome using new data sources. First, we have the type of misunderstandings to which we have already alluded through the example of Wagner. There is a genuine if relatively small scope for such misunderstandings to shape research outcomes. The second issue concerns what it is that respondents are prepared to reveal. On a very basic level this would include response rates: this is a measure of people not being willing or having the interest to reveal anything. This problem though would also extend much further than this to include the impact of respondents' own Goffmanesque presentations of self an awareness that we can imagine is magnified where we are attempting to find out about such things as cultural capital (which is of course a product of social reading, game playing and self-positioning). The reported set of preferences and tastes are likely to be shaped by aspirational positioning, understandings of what is a good thing to declare a preference for and so on. The third issue we identify concerns what has been described elsewhere as the sociological problems associated with being uncool (Beer 2009). The argument here concerns the ability of the researcher to keep up with culture to enough of an extent that they can see and therefore research cultural movements. This work argues that different stages in the life cycle of the researcher afford different critical distances between themselves and their object of study. These three issues we would describe as being quite fundamental issues that are really debates for the methods textbooks to ponder; rather than elaborating on these further here let us instead focus on an issue that is more central to the way we understand cultural formations such as field. This is the issue of how we approach genre, and in particular how we draw the boundaries of genre within the research process.
2.3 Whilst much of the more historically orientated or humanities based research into musical genres tends to acknowledge the dynamism of musical genres, and of genres more generally (DiMaggio 1987, Negus 1999, Frow 2006, Dowd et al. 2006), sociology tends to work with quite fixed notions of genre (Beer 2013). These fixed genres often form the basis of survey or interview questions and inform the way that we categorise the space within field. These established notions of genre, drawn around things such as 'heavy metal', 'pop' and 'classical', become the force fields and boundaries within field that afford an understanding of the tensions and differences that are central to understanding the connections between cultural taste and social division. Genres matter here because they ultimately feed into sociology's conceptions of difference, class and inequality. Genre is often a predetermined aspect of the research and as such shapes the boundaries drawn within field, which then feed into conceptions of social divisions (see for example the influential work of Peterson and Kern (1996), Chan and Goldthorpe (2007), or even the current Great British Class Survey (Savage et al. 2013)). These boundaries are then used to highlight tensions, to understand boundary crossing and eclecticism and to understand the linkages between culture and social divisions. Even when we are looking at the complex diagrammatical depictions of field typical of something like multiple correspondence analysis, we are still of course looking at individuals placed geometrically by the similarities and differences in their preferences for a few pre-set genre categories. We could say that these genre categories, and the perception of them as fixed, stable and mutually understood rather than vibrant, changeable and contextual, has had a significant impact upon our understanding of taste and field. The nature of survey research itself means that top-down genre categories as imposed by researchers even if they are up-to-date when a questionnaire is initially designed will end up dated when respondents find themselves filling it out. There are, we would suggest, problems here that are limiting our understanding of these important issues and which need to be rethought. We are simply not getting at the complex intensities of musical taste and preference and we are not fully capturing the lively, mobile and fluid aspects of field dynamics (Beer 2013). To foreground our argument, we need, as Lamont helpfully puts it, to focus upon 'studying classification systems comparatively and from the ground up' (Lamont 2010). As we show in this article, using digital data for ground-up approaches to taste calls into question existing visions of genre stability in sociological accounts of taste and social class.
2.4 To understand the sociological relevance of everyday engagements with music, particularly at a quantitative level, we need to take Lamont's advice and apply it to conceptions of genre (again, see Beer 2013). The problems as we see it are twofold. First, we have become perhaps too reliant upon imposing categories, boundaries and connections in cultural analysis. This involves a pre-set array of genres which are used in the processes of differentiation, with respondents selecting from genres and indicating something of the order of their 'like' or 'dislike' (again the recent BBC Great British Class Survey follows this format). We might imagine that genre titles like 'classical' or 'folk' are likely to have very different boundaries depending upon who is drawing them for instance classical music might be Katherine Jenkins or Webern, similarly an artist like Eminem might be pop for one person and hip-hop for another, Oasis might be rock for one person and pop for another and so on. In other instances the emphasis is placed upon the research team to create connections between artists and genres (Savage 2006, Bennett et al. 2009). In these circumstances the researchers decide which artists are representative of which genres and then work from there. There is an emphasis here upon the researcher to connect genre and artist. This then is not just an issue for quantitative research. We can imagine researchers using individual artists as prompts for genres in interview settings.
2.5 The above outline suggests that we are faced with some problems in developing our understandings of field and in working with genre. On this issue Mike Savage makes the following point:
'We cannot be sure that respondents have similar understandings of what music is entailed in particular genres, and we probably do not know if people who do not like genres genuinely do not like them, or have not heard of them...If we are to get at key distinctions in musical taste, we need to ask about taste for particular works of music as well as about broadly defined genres.' (Savage 2006: 162).There is a sense then that we need to account for musical tastes and preferences by understanding genre but by also understanding attachments and preferences for particular artists. As Savage argues here, we need to make visible specific tastes in works and artists as well as broadly defined genres. There is a sense here of a need to develop a more fine-grained or granular analytical precision in field analysis that enables connections and linkages to be observed so that we might gain greater insight into the intricacies of musical taste and consumption. We would add to Savage's point though that we should also look to work beyond either individual works or 'broadly defined genres' and toward the vast, mobile, relational and variable versions of genre that define and shape taste, and which then feed into the formation of social bonds and divisions (Beer 2013). There is of course qualitative work that attempts to unpick genre from the ground-up (see for example Atkinson 2011), which can successfully allow genre to be accounted for on a small scale and as a part of everyday cultural practice. The promise of the type of digital data we discuss below is that it enables us to see this ground up vitality but on a larger scale and to look beyond reported accounts of taste. We should also note elsewhere the use of other types of data to see genre changes and vitality. These include van Venrooij's (2009) use of music reviews and Lewis et al.'s (2008) focus upon declared preferences and friendship connections on Facebook.
2.6 The above leads us to consider the part that methods play in researching and constituting field. John Law (2004) has focused upon extending established debates about the ways in which methods play a part in creating or 'enacting' rather than simply reporting on phenomena: particular methods both enact particular elements of the social world and omit other elements. While we do not suggest here that we can escape this performance of method or the enactment of particular realities, we do suggest that the package of methods we are working with in understanding cultural fields performs a certain kind of reality to which there are alternatives, and that we can now open up some of the aspects of field that we are currently shutting down. The existing approaches toward understanding genre are one example within which the conception of field is being shaped or enacted in a particular direction.
2.7 It is interesting and perhaps revealing that in their major and groundbreaking study of the relations between culture, class and distinction, Bennett et al., who are working with the more traditional Bourdieusian methodological toolkit, make the following point:
'whilst in the 1970s and 1980s Bourdieu was swimming against the tide in continuing to champion field analysis, recent developments, notably the potential offered by new forms of transactional data to conduct network analyses present new opportunities for field analysis.' (Bennett et al. 2009: 32)In response to this, and having raised some of the more hidden dimensions of the musical field, we will use the remainder of this article to explore the potential of some of these apparent opportunities. We ask simply what possibilities are present for expanding our repertoire and rethinking field analysis in these new digital social data. More specifically we are concerned with returning to Lamont's point by thinking classificatory systems from the ground up.
Revealing the musical field through by-product data
3.1 In order to elaborate the potential opportunities of by-product data for uncovering some of the hidden dimensions of the musical field we would like to focus upon a particular example within which musical taste might be captured for analysis. For this purpose we have chosen to use the online music application Last.fm, which works as follows. Users sign up to the site, choosing a username, which is then associated with a profile. These profiles develop in two ways. The first way is similar to the ways in which profiles are generated in many social networking sites: users can also choose to provide information on their gender, age, location, and so on.[1] The second involves their offering data about their own musical consumption. Those people using the desktop version (via iTunes, Windows Media Player, Rhythmbox, etc) install a piece of software, 'Audioscrobbler', which automatically uploads information about pieces of music listened to on the computer, or 'scrobbled'. Those using mobile versions, such as those people using devices running iOS or Android, in addition to those using Spotify, enter their Last.fm details into these devices, with information about the listening behaviour being uploaded (again, 'scrobbled') automatically. This generates a real-time history of the user's listening behaviour, generating charts of most-listened artists and pieces of music. This information then allows the website to suggest other artists and pieces of music to the user, based on profiles similar to the user's own, in a classical exemplar of 'knowing capitalism' (Thrift 2005). A user's profile is automatically updated with charts for the last month, three months, six months, and twelve months, and for their entire listening history. This therefore provides us with a wealth of information about real musical listening history, as opposed to expressed preferences. At the time of writing, Last.fm had a total userbase of more than 30 million profiles; while many of these profiles are dormant or unused, there is still a total database of more than 60 billion 'scrobbles'.3.2 Users can also interact with the site and each other: they can select tracks as 'loved tracks'; they can report friendships with other users (with Last.fm reporting the similarity between users' listening histories); they can join groups (which may eb based on shared interests in specific artists or genres, being in a shared location, etc); and they can communicate with each other on discussion boards, within groups, and in their own 'shoutboxes'. Although we will largely be focusing here on Last.fm as a record of musical consumption, these instances of communication also provide a wealth of qualitative information about musical engagements, tastes, preferences and also the interactions within which these are instantiated.
3.3 Data are also held about the artists and pieces of music that are listened to. Each artist has an allocated profile on the site, containing information about the artist in a wiki that can be edited by any user, previews of their music, similar artists, shoutboxes, and current listeners. The artist profiles also contain tags; any user can tag an artist with any label, most of which in execution are genre labels (the most popular being 'rock' and 'electronic'), but might be associated with something particular to the user ('seen live', 'albums i [sic] own', etc). This distinguishes Last.fm from other online services which impose strict genre distinctions such as Y!Music (Kibby 2006). The weightings of tags on artists' pages correspond to the number of times those tags have been applied; both Roy Orbison and BB King have been tagged with 'blues', but this particular tag is weighted much more strongly on King's page than on Orbison's. These tags can therefore be seen as a sort of bottom-up approach to genre classification. There is therefore a relationship between users' profiles and artists' profiles: not only are the descriptive elements of artists' profiles generated using users' free labour (for another example of 'fan labour' in the context of online music, see Baym & Burnett 2009), but the information about their listeners consists of aggregating data from users' profiles themselves.
3.4 As with all potential sources of digital by-product data, such as collections of preference data from Facebook and so on, not all Last.fm data will be completely clean: people might leave individual songs playing on repeat while muted overnight in order to artificially boost their play count of that song, and might also deliberately tag artist pages with abusive labels. However, we show that such problems should not substantially influence any analysis that we discuss.
Exploring existing revelations about the musical field
4.1 In this section we describe existing pieces of work demonstrating ways in which Last.fm data can be used to further the sociological understanding of music. We might begin thinking this through by returning to Mike Savage's (2006) excellent article on the musical field. In Savage's article we are faced with some visualisations of the 'structure of the musical field' that show connections between genre preferences. This is an interesting and revealing vision of musical taste patterns that shows how preferences might work across particular genres and not others. The problem here, as we have already suggested, is that we are working with data based upon reported music preference rather than actual listening patterns and, further to this, that we are working with a rigid and top-down drawing of genre classifications that then informs our understanding of the structure of the musical field (the same can be said of Chan & Goldthorpe 2007). It is not that this is a problem in itself, it is just that it shapes understandings of the musical field in a particular direction.
4.2 In terms of the depiction of genre in the structure of the musical field, Savage's visualisations contrast sharply with the visualisations provided by those playing with the Last.fm data resources. One important example is a visualisation titled 'islands of music'[2] which is available through the Last.fm 'playground', and which uses cluster analysis to map out the connections between music genres, or the 'structure of the musical field' (Savage 2006), for a random sample of 13,000 listeners (see Figure 1). This 'islands of music' visual shows varying size islands against a blue sea background, with each island representing a specified music genre. The size of each island reflects the level of consumption of music tagged with that particular genre title. The proximity of these genre islands illustrates the probability that people interested in one genre will also be interested in another. This exercise demonstrates the volatility of genres themselves, as determined by listener behaviour. This map depicts around 50 discrete genres, and hovering over the islands within it, and indeed over the sea, reveals many sub-genres within those larger genre categories. We are presented then with an almost unfathomable depiction of the complexity and intricacies of genre in musical taste as it happens. It is possible to draw a number of observations about musical taste from this visual. We can see for instance that those interested in psychedelic are also likely to have an interest in doom metal or folk, but they are unlikely to like hip-hop or emo: the long shaped island spread between these poles suggests that psychedelic is a quite varied field, ranging from 60s psychedelic on the end closest to folk to progressive rock psychedelic at the end closest to various types of metal. There is certainly little suggestion of the tension of vastly polarised genres but rather we see vast types of genre populating the middle ground between broader groups of genres.

|
| Figure 1. The 'islands of music' visualisation available on the Last.fm playground. |
4.3 We can also pick out some other observations, such as those who like ambient music are likely to avoid industrial metal, and so on. Classical has a moderate size presence and is located relatively centrally: this provides tentative support for the omnivore thesis, with classical listeners being more likely to listen to a wide range of other genres. It becomes clear from this that people could like multiple genres without necessarily having eclectic tastes, rather they could like a group of closely clustered genres. We can also immediately see that the population of Last.fm has a strong interest in various types of metal, with multiple versions clustering together. Indeed, we might be forced to think about how the aversion to particular genre categories might be at stake here, with different forms of 'subcultural capital' (Thornton 1995) operating amongst different groups and defining what type of classification systems and terminology should be used on the ground for describing musical preference and the like, thus leading to a genre splintering that is simply not visible in previous work on the musical field (Bennett 1999). As this brief description demonstrates, it is possible to tentatively derive some findings from this newly delineated vision of the structure of the musical field and point towards some future possibilities for further insights.
4.4 Without wishing to labour this point, the notable feature of this example is that it not only accounts for actual listening practices, but that it also draws upon the genres that these listeners themselves actually associate with particular musical works (either through tagging or simply by using these genre tags to navigate through the content). In this instance this has two clear benefits. First, it helps us to at least partially eliminate the problems of analysing both genre and works. We are not forced to impose genre structures on field and, because the music is tagged by participants themselves, there is not the necessity for the researcher to create associations between artists and genre categories. In short, and as with the analysis developed in the earlier parts of this article, the visualisation of the islands of music provides us with a vision of the structure of the musical field within which the organising classificatory system is drawn from the ground-up. The second insight it creates is that it clearly highlights the complexity of genre-in-action. It shows us, quite starkly, the limitations of the boundary conventions we use in genre and the musical field. This visualisation shows some of the intricacies of genre and field and illuminates the apparent inadequacy of established genre conventions in understanding musical taste and preferences (for a similar mapping of genre by information scientists see Biberstine et al. 2010).
4.5 Our second example of research using Last.fm is another case of examining the genre preferences and proximities of the Last.fm userbase, and resembles existing sociological research even more closely. Anthony Liekens, a postdoctoral researcher in the department of Molecular Genetics at the University of Antwerp, has made a large number of tools that facilitate research into this data. Liekens (2007) takes a sample of 2840 users, who, between them, have listened to a total of 28,302 discrete artists. He uses this data in order to generate tag vectors for these individuals. The tag vector is a summary by genre of an individual's top 50 most listened to artists. The length of each element in the vector is a function of both the artists listened-to and the tags within those artists. If an individual had a tag vector where one genre had the coefficient 1, that would imply that said individual exclusively listened to music that had only been tagged with the label in question. Those listeners with heavy consumption of a small number of genres will have the distributions of their vectors highly positively skewed.
4.6 Liekens then takes the top 10 genres within each individual's vector, leaving a total of 735 tag labels, allowing us to conceptualise the sample as 2840 points in 735-dimensional space. This is then reduced via principal components analysis to 4 dimensions, which allows him to graphically portray his sample in this space. This exercise demonstrates that the main initial point of divergence within the sample is between 'indie' and 'rock', which are negative on his first dimension, and 'electronic', 'hip-hop', and 'metal', which are positive. Clear differences emerge between 'electronic', 'hip-hop', and 'metal' when the further dimensions are visualised. The final stage is to use k-means clustering of these vectors in order to identify distinct groups of users by their consumption.
4.7 This piece of work is tremendously important for our purposes for a number of reasons. First, it is a clear application of social scientific methodology to the Last.fm dataset, using traditional statistical methods in order to identify distinct groups of musical consumption, based (once again) on real, rather than reported, consumption patterns. Second, as an independent piece of research it reveals a large number of findings of interest to those people interested in the sociology of culture. For example, in analysing the boundaries between genres, it reveals that the metal cluster is the quickest to break up, with the electronic cluster, in spite of seeming to contain a number of disparate subgenres, remaining relatively internally coherent; in addition, in finding that the hip-hop cluster is the furthest from any other, we might infer that hip-hop listeners are the least likely to listen to other types of music. Third, and crucially, it tells us some important things about the limitations of Last.fm's sample: an obvious criticism of using Last.fm data is that its userbase is not representative of the general population, and these results indicate to us in what ways this is true. The key difference between these visual islands of music and Liekens' map of users' preferences from a methodological perspective is the traditional distinction between case-based and variable-based analysis: while the islands of music show the relationships between genres, Liekens' map shows the similarities between users.
4.8 We now move towards investigating variation within Last.fm users: in what way are those with different demographic characteristics distinct from each other? We continue to analyse specifically visual analysis that enable us to see further the divisions of the musical field on a quantitative level. The blogger and Last.fm intern Joachim Van Herwegen has used available data to create visual representations of musical preferences based upon gender (on the vertical axis) and age (on the horizontal axis). Two visualisations have been created, one comparing tag preferences (mostly genre based) and one comparing artist preferences. The size of the font (of the particular artist or genre) on the table shows the relative frequency of its play. The best thing to do to understand this is probably to visit the Last.fm blog to see the images <http://blog.last.fm/2010/09/22/now-in-the-playground-gender-plots>. We can locate many insights from these visualisations. For example, we can see that the band Radiohead are favoured by the relatively young (those in their 20s), and that they are relatively gender neutral in terms of their consumption. In terms of genre we can see that the genre 'math metal' is almost entirely a young male musical preference and 'powerpop' is the preference of young females, and so on.
4.9 While this existing work demonstrates to us what the major trends are in the Last.fm population, there is another tool which can be used to establish how different an individual user is from the population mean, which might otherwise be considered as the eclecticism of musical taste, and in so doing we can tap directly into the far-reaching and prominent debates on cultural omnivorousness (Peterson & Kern 1996), the presence and importance of which has been very widely debated by cultural sociologists (see for example Warde et al. 2007). To return to Liekens' analytical work, he has created an application linked here that measures how eclectic the musical taste is of any specified Last.fm user. The user's username is entered into the application and a 'super-eclectic' score is generated for that individual.
4.10 The super-eclectic score, we are told, takes the top 50 most listened to artists for the selected individual's profile and measures how different these artists are from each other. For each most-listened-to artist, the tool finds the five most closely related artists, and counts the number of unique most closely related artists across all 50, generating a score out of 1000 for their eclecticism. We tested the example of the second named author, whose profile generated a 'super-eclectic' score of 819/1000. This, the application tells us, is a high score that commands 'bragging rights', above the threshold of 700/1000 we can see here that eclecticism is assumed to be a positive characteristic that evokes cultural capital. By way of a point of comparison the application also provides us with the (approximately normal) distribution of the super-eclectic scores of the entire population of Last.fm users, this enables the visitor to position the individual score against the rest of the Last.fm population it also reveals the level of eclecticism of this sizeable population. Clearly then the capacity to measure omnivorousness based upon actual music consumption is something of a breakthrough in the understanding of eclecticism in music taste, which we have already noted has become a crucial issue in cultural sociology's understanding of the class/culture nexus.
4.11 As a final, and brief, exploration of existing pieces of work using Last.fm data, we point towards Last.fm as a longitudinal as well as cross-sectional dataset. Our previous examples pointed towards people's overall levels of consumption of pieces of music, artists, and genres; while this is appropriate for a wide range of questions, for other questions it is more appropriate to investigate people's musical life courses. This can be demonstrated through Last.fm's highly revealing and analytic 'Best of 2011', available at <http://www.last.fm/bestof/2011/>. Previous years' 'Best of's included editorial content on the most listened-to artists of the last twelve months based on Last.fm data. However, the 2011 charts were augmented in two key ways. Firstly, there is also a chart for 'New Discoveries': those artists who had never been scrobbled before 2011, allowing us to see the relative successes of brand new artists (those emerging into the musical field). Secondly, the user is able to filter both by tag and by location, allowing charts by genre, and also by country. We can use this data to investigate crossnational differences in tastes; we can see that three of the top 100 artists by US listeners were primarily tagged 'dubstep', whereas seven of the top 100 artists by UK listeners were. However, the 'year in music' tab shows us some fascinating results, the presence of which raises the possibility of an enormous amount of research options. This tab shows the listening frequency to a few artists across the previous twelve months, demonstrating the effects of external shocks on listening behaviour. The shocks in question are three deaths (Amy Winehouse, DJ Mehdi, and Heavy D), three breakups (The White Stripes, LCD Soundsystem and REM), a reunification announcement (the Stone Roses), a 70th birthday (Bob Dylan), and three varied years (PJ Harvey's new album and subsequent awards from NME and the Mercury Prize; David Hasselhoff's tour and birthday; and Beyoncé's new album and pregnancy announcement). These data, shown graphically, demonstrate that deaths in particular have an enormous effect on the consumption of an individual artist's music. While this is not surprising, the magnitude might be, with almost-identical tenfold increases for all three artists whose deaths are highlighted. This is a demonstration of the power of the data; we can imagine more generally that there are external events which might influence overall levels of musical consumption, particularly among subgroups, which might be of interest to the sociological community. An understanding of cultural reverberations suggests itself here. These graphs show that the magnitude of these events can be established. Currently, estimates of the impact of external shocks on people's musical consumption can only easily be established via sales data; compared with Last.fm data, these might lead us to overestimate the effects of shocks on people's consumption, as sales data bias our measures towards people who didn't previously own the recordings by the artists in question. While Amy Winehouse's death led to a tenfold increase in consumption of her music on Last.fm, this is dwarfed by the increase in her album sales, which increased by 37 times overnight after her death (Topping 2011). This data therefore allows us to get a more rounded picture of the effects of shocks on the consumption of artists' uvres. Indeed, Last.fm data has at least two further advantages over sales data for its population of users: firstly, sales data indicates nothing about how frequently people actually listen to the records they buy, and secondly Last.fm data also captures music listened to through Spotify, illegally downloaded, and so on. This opening outline gives a sense of how sociologists might develop more nuanced understanding of cultural tastes and the impact of social events.
Using and adapting existing data
5.1 In addition to investigating presentations of outward-facing data on Last.fm (whether already aggregated or not), we can straightforwardly sample in order to get at groups who are relevant for our interests in terms of addressing existing questions (see for an example Baym & Ledbetter 2009). For example, we have already demonstrated some of the issues surrounding the use of genre as a useful concept given the top-down approach in survey research. In this regard Last.fm presents some opportunities, particularly as we revisit the cultural omnivore debate (which we have shown is a central debate in cultural sociology and its conception of class). Survey researchers often ask for respondents' stated preferences for a given set of genres, identify patterns of responses, often drawing conclusions consistent with the omnivore thesis: some people (univores) have a preference for, or listen exclusively to one genre (usually pop/rock); other people (omnivores) have a wide range of preferences, including genres usually understood to be highbrow (usually classical) in addition to that one genre to which univores listen. This can be, and has been, criticised for being reductive (for a recent example see Savage & Gayo 2011), with criticisms generally focusing on the lack of information on genuine preferences which can't be satisfied using survey methods. It should not be possible to apply these criticisms to a study using Last.fm data. Instead of forcing a small number of genre labels, or a select few pieces of music, onto respondents, we can use real-life musical consumption data. A suggestion for a more in-depth project follows in the next section.5.2 Entertaining the omnivore thesis, we should expect that the musical consumption of listeners to stereotypically 'lowbrow' music would appear less omnivorous than the musical consumption of listeners to stereotypically 'highbrow' music. Alternatively: we expect listeners of individual rock bands to be less omnivorous than listeners of individual classical composers.
5.3 Simply as a brief and fairly crude illustration, we therefore take a random sample of 30 of the 'top listeners' of each of the artists on Last.fm who have most frequently been labelled with the tags 'rock' and 'classical', who as of 6 February 2012 were Red Hot Chili Peppers (RHCP) and Wolfgang Amadeus Mozart (WAM) respectively. Using Liekens' tool, we then generate their tag vectors. If our extremely basic account of the omnivore thesis holds up, we would expect that the average weighting of the #1 tag for RHCP listeners would be greater than the #1 tag for WAM listeners; to put it another way, we expect a higher proportion of rock listeners' musical consumption to be their most preferred genre than classical listeners'. The other side of this is that we expect classical listeners to have a longer tail of genres: while the univores' consumption will be heavily skewed towards a small number of genres, leaving little time for any others, omnivores' will be more evenly distributed. We observe the square roots of the sizes of the top 20 heaviest weighted genre for each individual, take the means of those sizes and generate cumulative distribution functions for each subgroup, which generates the following results.
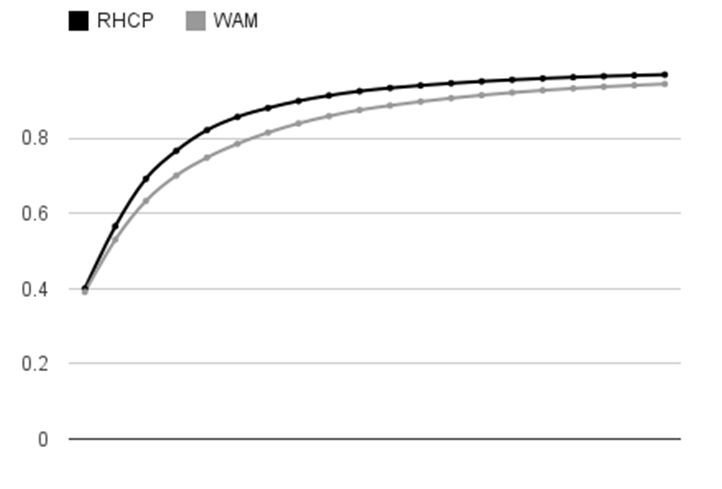
|
| Figure 2. An illustration of number of genres consumed by our subgroup. |
5.4 These results indicate (see Figure 2) that while our first hypothesis fails, with the mean sizes of the most prominent tag for both our subgroups being almost identical, our 'long tail' hypothesis does appear to hold up: our RHCP-listening subgroup listens more to a small number of genres than does our WAM-listening subgroup, with our WAM-listening subgroup appearing to have a longer tail. In line with this article's aim to demonstrate the potential of this data, the next stage in this analysis is to investigate this in more detail; while these results are consistent with the omnivore thesis, they are not sufficient to demonstrate unquestionably that it applies to our sample of Last.fm users. Again this intimates new possibilities for interrogating sociologists' existing accounts of eclecticism in cultural tastes, and then ultimately what this means for the formation and maintenance of social hierarchies.
Potential and actual new data sources for the sociological imagination
6.1 Indeed, there is a more substantive potential criticism of the omnivore thesis, which can be addressed using Last.fm data. It is easy to imagine an account of the omnivore thesis in which our elites' consumption of 'rock/pop' (the most frequently used basic category) consists primarily, if not exclusively, of the music of their childhood (for more on the ongoing attachment to music through the lifecycle see Bennett 2006). This may not be the case for univores' consumption of 'rock/pop'. If, actually, there is no overlap between the 'rock/pop' consumption of the two groups omnivores listen to Led Zeppelin, univores listen to Rihanna, say the food metaphor cannot sustain itself and the omnivore thesis fails. We therefore propose an exercise in which we identify potential omnivores and potential univores in our sample: our omnivores might be those people whose genre vectors have particularly long tails, and our univores might be those whose tails are particularly short. We can then investigate the actual artists that both of these groups listen to in their shared genres, which may or may not be pop/rock (a genre which only very rarely emerges in the Last.fm data). If the overlap within these genres is small, this would provide major refutation to the omnivore thesis; if it's large, major support.6.2 Ideally, then, what we want is a large-scale dataset containing all individuals' charts for a given time period: the number of times each user has listened to each artist. This can then be used to identify charts for all users' top 20 artists (or top 10, or top 50 ), with these charts being used in order to identify the whereabouts and persistence of omnivores and univores. A univore might be identified as someone for whom the largest single genre element within their tag vector is greater than 0.8; an omnivore might be identified as someone with more than three genres with vector elements greater than 0.4. These charts can then be revisited in order to compare the artists within rock/pop (or equivalent) consumed by both groups.
6.3 Such a dataset already exists and is available at <http://www-etud.iro.umontreal.ca/~bergstrj/audioscrobbler_data.html>. This dataset contains the entire musical consumption history for the userbase of Audioscrobbler up to 6 May 2005 (before the formal merger between Audioscrobbler and Last.fm). It contains the entire dataset for the userbase at the time, of about 150,000 individuals, who between themselves were reporting about 2 million scrobbles per day, generating a total database of about half a gigabyte.
6.4 The dataset itself consists of four files, of which one is a readme. The first file contains three columns: the first column includes IDs for each unique username, the second contains IDs for each unique artist name, and the third contains the relevant number of plays. So, for example, the line '2101715 1233770 32' means that user 2101715 has listened to artist 1233770 on 32 occasions. The second file contains two columns: the first is the artist ID number, and the second is the artist name. This can be combined with the first file to provide charts for all users, providing information about who the artists are: this can then be used to generate tag vectors for each artist, and for each user. To extend our previous case, we can combine this file with the line '2101715 1233770 32' to learn that user 2101715 had listened to The Shins 32 times. The third file contains known incorrectly spelled artist IDs, and the corresponding correctly spelt artist IDs. This can be combined with the first two files to clean the data, avoiding the situation in which users listening to music reported as being by Bjork, Björk, and Bjørk have them classified separately.
6.5 These files can be combined to generate a data matrix, with artists as columns and users as rows, for an enormous database of actual musical consumption. While we have set out here an application of this data that can directly address a current sociological puzzle, the data is not limited to this, particularly given that we can combine this consumption information with demographic information about the users themselves.
6.6 In addition to this, while the previous few applications all treat individuals' consumption as fixed, taking a snapshot over a given period of time, the data can also be treated as longitudinal. This has already been shown in the first example, observing the changes in consumption of individual artists and pieces of music over time; we can also observe changes in individuals' consumption over time. While each user's profile contains summaries of their overall behaviour in the form of charts, they also contain their precise listening behaviour, timestamped, available at last.fm/user/(username)/tracks. This data can be explored to investigate, as Atkinson (2011) describes it, ' (t)he context and genesis of musical tastes': for those people who have been members of the site for some time, we can investigate how their musical tastes develop. This can be developed further: if we combine this longitudinal data with the data on relationships provided by users on Last.fm itself, we can investigate whether friends' musical tastes will become more similar over time, as predicted by Lewis et al. (2008) for preferences reported on Facebook. This final potential dataset has some enormous advantages in terms of the questions it can answer, relating as closely to literature on time use and lifecourse as it does to literature on the sociology of culture. Its major disadvantage is its sheer size, both in terms of the effort necessary to create and manage it, and in terms of the massive demands that analysing it would place on any computer. It would dwarf the 2005 dataset, itself a significant undertaking for the social scientist (see Abbott 2000). These are massive data sets about tastes and trends.
The possibilities and limitations of by-product data
7.1 Given that one of the guiding aims of this article is to both provide insight into the musical field whilst also considering the relative potential of these new data, it is worth reflecting very briefly upon the value and limitations of digital by-product data. We should be clear that we are not suggesting that we abandon our established methods, but rather that by taking a considered approach we might be able to open up new dimensions to cultural analysis. Let us begin by quickly reiterating the more obvious advantages of this type of digital by-product data. These advantages would include the following: it captures and may reveal actual rather than reported practice; it doesn't require a large or expensive research infrastructure; it bypasses (some) difficulties of survey and interview research (such as falling participation rates and so on); music genres are tagged to particular songs and artists by the music community so the researcher doesn't require predetermined songs or genres; there are ready-made large and sortable populations of users; the data is supported by a culture of visualisation, that is to say a population of users who are playing with and creating insights into their own collective practices through data-play; and finally, as we have shown, there are large and freely available data sets to be extracted or created.7.2 Despite what looks likely to be some genuine potential for generating new insights into cultural preferences we would like to balance this enthusiasm with some caution. Clearly new forms of analysis of emergent digital by-product data are not a panacea. As we would expect, they bring with them their own limitations and issues that need to be considered as we evaluate how we might proceed. These limitations will vary in the way that the data will vary. Some of the forms of information we will extract will be more helpful than others. Indeed, general by-product data is messy and chaotic, it is often vast and sometimes unfathomable. The problem is of course that this data is not created with social research in mind; it has not been engineered for this purpose. And so we cannot expect it to match with or satisfy our research questions, we are not designing the data to suit the objectives of the social researcher. With this broader set of issues in mind, let us offer some reflections on the possible limitations based upon the particular case-study carried out here, these then may feed into more general issues to be considered further.
7.3 First, it is notable that these profiles don't tell us what the individuals do not like, the profiles only indicate what they consume or what they have indicated that they love. This makes it harder to measure dislike in understanding taste (although the importance of dislike and antagonism in understanding taste and division has recently been downplayed by Warde 2011). Many of the qualitative comments on the profiles provide some insight into negative responses to music, but this is much harder to gauge at a more quantitative level. Second, Last.fm, like many sites of cultural consumption, is shaped by predictive analytics. It is therefore entirely possible that profiles could be a product of the predictive analytics rather than active consumption patterns on the part of the listener. The predictive analytics might even be getting it wrong but the track might still be listened to. So the capturing of number of plays is not necessarily exactly the same as a record of preference. Third, and related to this, these profiles mainly track consumption and do not really capture the meanings, experiences or emotional attachment to songs or artists (although some of this is present in the qualitative comments on the profiles). Fourth, we have the obvious issue that people consuming Last.fm are likely to be relatively web-savvy people with particular types of taste, they are unlikely to capture those exclusively interested in vinyl culture for example or others who still focus music consumption upon other material objects like CDs. Fifth, there is a lack of depth of personal information available on some profiles (assuming the available information is accurate in the first place). This lack of personal information about participants limits some aspects of the analysis in this specific case. As a corrective though we would suggest that we need a more rounded understanding of the formation and flows of by-product data, how it is generated and who is playing with it before we rush head-long into any unreflexive analytical practices.
Conclusion
8.1 The first thing to say in conclusion is that this article is clearly not comprehensive in its re-imagining of the musical field or of sociological research more generally. This is an exploratory piece that has sought to scope the possibilities of a new understanding of field through by-product data. Our hope is that the article has provided sufficient insight to have given the reader some new perspective on how the musical field appears when viewed through an alternative informational resource, and that this vision can already be seen to reveal and possibly contrast with our existing visions of musical taste and preference.8.2 We began by sketching out some hidden dimensions of the musical field, and we suspect that this has generated a varying response amongst readers. The more significant observations made about our current approach to the musical field concerned the drawing of boundaries around genre, and the way that genres are linked to individual musical works or artists. We have argued in this piece that in understanding musical field there is a tendency to treat genre as a stable classificatory system with shared and universally understood boundaries. There is also a reductive tendency toward genre as a classificatory system, with researchers tending to draw upon a few well-worn genres (this is widely held to be the standard approach in measuring music taste, for example eight genres are used in the case of the influential study by Chan & Goldthorpe 2007: 6). These stable meta-genres are papering over the fragmentation, complexity and intensity of genres in everyday musical consumption: the Last.fm islands described in this article shows just some of the complex intricacies and vitality of genre-in-action, with the promise that there is more to be revealed. This complexity and intensity is simply being missed where we approach genre as a stable set classificatory system that can be routinely used to measure and organise a musical field. This is a significant problem, as we are just not able to use these fixed and more than likely out-dated genre classifications in order to see the musical field (or any field for that matter). Our argument in this article is that there is some scope in digital by-product data for accessing some hidden dimensions of the musical field, for approaching genre, as Lamont puts it, by 'studying classification systems comparatively and from the ground up' (Lamont 2010: 132). With digital by-product data such as that on Last.fm we can see actual music consumption and the actual genre classifications used in the everyday practice of music consumption and meaning making. In short, there is some potential here for looking at musical taste and the making of genre from the ground up. The least we can see from the examples discussed is that notions of lowbrow and highbrow simply do not cut it as a representation of the small scale meanings and belongings happening in the musical field and that our conception of genre is currently obscuring the complexity of the musical field that we have seen through this by-product data we have also intimated to how concepts like the omnivore might be re-imagined through this data. The potential here then is for this new digital data to be used to intervene in existing sociological visions, to reframe established understandings and to rethink the linkages between taste and social difference.
8.3 What we see on Last.fm is the deployment of a kind of classificatory imagination in progress (Beer 2013). The meta-data organising and searching of the music is a product of interactions and 'tagging' by the people who are engaging with the music. This classificatory imagination the application, deployment and play with classificatory system such as genre is a crucial factor often missing in accounts of field. We often imagine field simply to be defined by very little classificatory imagination on the part of the people involved in music consumption. This, as shown here through the example of Last.fm, is an assumption that needs to be reconsidered. Rather this classificatory imagination is powerful and active in shaping the musical field. In order to redraw field we should now explore how we can use this type of new social data further in our work. On one hand we might look to extract data and adapt our methods to analyse them, on the other hand we might also wish to explore how we might critically analyse, commentate on or even appropriate the outputs of those who are working or playing with the data. This will mean looking beyond the academy to see how 'ordinary people' are playing with the data themselves, how interns of companies are using it to understand and visualise their 'customers', to see what computer scientists and the like are producing with the data, to see what artists and others are creating with it. This article engages in both practices and suggests that we can both learn from the raw data and from the things that various agents are doing with these data.
8.4 This, of course, is not to suggest that we abandon the established methods of surveys and interviews and replace these with an unflinching 'digital methods'. Far from it. Rather, we would argue that this digital by-product data, the new forms of social data that accumulate in a digital and information dense mediascape, provide us with potential opportunities for revealing things that are perhaps not made available through our existing methodological repertoire. We need a considered approach to this. We need to understand how this by-product data is formed, how it circulates, and what agendas inform its production. We need to be alive to its limitations so that we might engineer case studies that draw upon a range of resources and techniques. This new data cannot tell us everything but it does have the potential, if used well and if used as a complementary arm in our methods portfolio, to re-energise social research and to provide us with a means to respond to the distinctive contemporary challenges that we face. In some instances we might use these new methods as stand-alone forms of inquiry, elsewhere we might adapt to interface these new data and methods with our established mixed-methods approaches. Our hope is that this article provides some substantive insights into the potential of these new social data and in so doing it begins to demonstrate how we might proceed with this adventure.
Notes
1 The search function on Last.fm allows the entire community of users to be searched through a combination of gender, age range, country, 'About me' keywords, music taste, if the profile contains a photo, most recently active profiles.2 The creators have provided a quite detailed description of how the map was created, a description that illustrates the level to which sociological methodology is to be found far outside of the territory of academic social science:
'The islands of music playground demonstration is something like a tag cloud where similar tags are located close to each together. The map was created using clustering algorithms The map is a self-organizing map of 13,000 randomly sampled Last.fm users labelled with tags and artists associated with each user. Each of these 13,000 users is described with a tag cloud which is extracted from the music the user listens to. This data is normalized One consequence of this is that a large part of alternative indie rock pop is averaged out. After all the normalization and pre-processing the 13k users are represented by 2000 distinct tags resulting in 13k sparse vectors in a 2k-dimensional tag vector space. Using singular value decomposition (SVD) the dimensionality is reduced to 120 dimensions. This 120-dimensional space is a latent semantic space in which no distinction is made, for example, between brazil and brasil. Using k-means clustering 400 prototypical users are computed. Users very close to the zero-vector are not considered for further analysis. ( .) Using a self-organizing map (SOM) the latent space is mapped to a 2-dimensional visualization space. The SOM has a size of 20 rows and 40 columns. A smoothed data histogram of the SOM is computed and visualized so that clusters show up as islands.'
References
ABBOTT, A. (2000) 'Reflections on the future of sociology', Contemporary Sociology, 29(2) p. 296300.ATKINSON, W. (2011) 'The context and genesis of musical tastes: omnivorousness debunked, Bourdieu buttressed', Poetics, 39(3) p. 169186.
BAYM, N. and Burnett, R. (2009) `Amateur experts: international fan labour in Swedish independent music'. International Journal of Cultural Studies, 12(5) p. 433449.
BAYM, N. and Ledbetter, A. (2009) 'Tunes that bind?', Information, Communication & Society, 12(3) p. 408407.
BEER, D. (2009) 'Can you dig it? Some reflections on the sociological problems associated with being uncool', Sociology, 43(6) p. 11511162.
BEER, D. (2013) 'Genre, boundary drawing and the classificatory imagination', Cultural Sociology, 7(2), forthcoming.
BENNETT, A. (1999) 'Subcultures or neo-tribes? Rethinking the relationship between youth, style and music taste', Sociology, 33(3) p. 599617.
BENNETT, A. (2006) 'Punk's not dead: the continuing significance of Punk Rock for an older generation of fans', Sociology, 40(2) p. 219235.
BENNETT, T., Savage, M., Silva, E., Warde, A., Gayo-Cal, M. & Wright, D. (2009) Culture, class, distinction. London: Routledge.
BIBERSTINE, J., Duhon, R.J., Börner, K., Hardy, E., and Skupin, A. (2010) 'A semantic landscape of the Last.fm music folksonomy using a self-organizing map'. Available from <http://cns.iu.edu/research/InTermsOfMusic_5Levels_Masked_a9.pdf> (accessed March 2nd 2011).
BOTTERO, W. & Crossley, N. (2011) 'Worlds, fields and networks: Becker, Bourdieu and the structures of social relations', Cultural Sociology, 5(1) p. 99119.
CHAN, T.W., & Goldthorpe, J.H. (2007) 'Social stratification and cultural consumption: music in England', European Sociological Review, 23(1) p. 119.
DIMAGGIO, P. (1987) 'Classification in art', American Sociological Review, 52 p. 440455.
DOWD, G. Stevenson, L. and Strong, J. (2006) Genre matters. Bristol: Intellect.
FROW, J. (2006) Genre. London: Routledge.
LAMONT, M. (2010) 'Looking back at Bourdieu', in Silva, E. & Warde, A. (Eds.), Cultural analysis and Bourdieu's legacy: settling accounts and developing alternatives. London: Routledge. p. 128141.
LAW, J. (2004) After Method: mess in social science research. London: Routledge.
LAW, J. (2009) 'Seeing like a survey', Cultural Sociology, 3(2) p. 239256.
LEWIS, K., Kaufman, J., Gonzalez, M., Wimmer, A., and Christakis, N. (2008) 'Tastes, ties, and time: A new social network dataset using Facebook.com', Social Networks, 30, pp. 330342.
LIEKENS, A. (2007) 'Data mining musical profiles'. Retrieved 6 February 2012, from <http://anthony.liekens.net/index.php/Computers/DataMining>
KIBBY, M. (2006) `Radio that listens to me: Y!Music web radio', Australian Journal of Emerging Technologies and Society, vol 4(2,) p. 8193.
NEGUS, K. (1999) Music genres and corporate cultures. London, Routledge.
PETERSON, R.A. and Kern, R.M. (1996) 'Changing highbrow taste: from snob to omnivore', American Sociological Review, 61(5) p. 900907.
PRIOR, N. (2008) 'Putting a glitch in the field: Bourdieu, actor network theory and contemporary music', Cultural Sociology, 2(3) p. 301319.
SANTORO, M. (2011) 'From Bourdieu to cultural sociology', Cultural Sociology, 5(1) p. 323.
SAVAGE, M. (2006) 'The musical field', Cultural Trends, 15(2/3) p. 159174.
SAVAGE, M., Devine, F., Cunningham, N., Taylor, M., Li, Y., Hjelbrekke, J., Le Roux, B., Friedman, S. & Miles, A. (2013) 'A new model of social class?: findings from the BBC's Great British Class Survey experiment', Sociology, 47(2) p. 219-250.
SAVAGE, M. and Gayo, M. (2011) 'Unravelling the omnivore: a field analysis of contemporary musical taste in the united kingdom', Poetics, 39(5) p. 337357.
THORNTON, S. (1995) Club cultures: music, media and subcultural capital. Cambridge: Polity Press.
THRIFT, N. (2005) Knowing capitalism. London: Sage.
TOPPING, A. (2003) 'Amy Winehouse's family pay tributes as album sales surge', The Guardian, July 11. Retrieved 6 February, 2012, from < http://www.guardian.co.uk/music/2011/jul/24/amy-winehouse-death-family-statement>
VAN VENROOIJ, A. (2009) 'The aesthetic discourse space of popular music: 19856 and 20045', Poetics, 37(4) p. 315332.
WARDE, A. (2011) 'Cultural hostility reconsidered', Cultural Sociology, online first, published online 25 March 2011 [doi://dx.doi.org/10.1177/1749975510387755]
WARDE, A., Wright, D. & Gayo-Cal, M. (2007) 'Understanding cultural omnivorousness: or, the myth of the cultural omnivore', Cultural Sociology, 1(2) p. 143-164.
